

Yet Another Epidemiological Hatchet Job on Causality Fails to Exonerate the Exposure via Hidden Collider Bias. This Time, It's Fluoride.
You cannot adjust for correlates of the exposure, direct or indirect, to exonerate the exposure. Smoking, lead, thimerosal, aluminum, glyphosate... and now fluoride. We are not fooled that easily.

You would think that a study examining over 2,600 children’s cognitive scores using the WAIS-IV, complete with a sophisticated fluoride exposure metric and a tidy suite of statistical controls, would finally put the fluoride–IQ question to rest. You would think it exonerates fluoride.
It doesn’t.
Let’s unpack exactly why.
The Surface Strengths
The new study by Do et al. (2024), published in the Journal of Dental Research, has all the hallmarks of credibility. The authors drew on the Longitudinal Study of Australian Children (LSAC), one of the country’s premier national birth cohorts. Fluoride exposure was estimated via percent lifetime access to community water fluoridation—a more refined method than spot urine levels or retrospective surveys. Cognitive performance was measured using the WAIS-IV, a full-scale IQ instrument administered by trained psychologists. And the statistical models adjusted for a seemingly exhaustive list of covariates: parental education, income, Indigenous status, geographic remoteness, breastfeeding duration.
On the surface, it reads like a model study in public health epidemiology.
But causality is not determined by surface. It is determined by structure. And this model is structurally flawed. They also adjusted for early-life toothbrushing habits. and neurodevelopmental diagnosis.
The Toothpaste That Erased the Exposure
At the center of the model’s collapse is a single analytic decision: the inclusion of toothbrushing with fluoridated toothpaste at age two as a covariate. And neurodevelopmental diagnosis.
At first glance, it seems reasonable. After all, fluoride doesn’t just come from drinking water—it comes from toothpaste, supplements, dental treatments, and other sources. But here’s the problem: brushing with fluoridated toothpaste is not a confounder to be “adjusted for”. It’s a component of the exposure.
And neurodevelopment diagnosis can occur downstream of fluoride exposure.
When a child brushes with fluoridated toothpaste—especially at age two, when swallowing is common—they absorb fluoride. That contributes to total fluoride burden. By adjusting for this variable, the authors are not isolating fluoride’s effect. They are amputating a key portion of it. The model ceases to estimate the effect of cumulative exposure to fluoride on IQ, and instead estimates the effect of fluoride minus the portion from brushing.
Adjusting for neurodevelopmental diagnosis is even more disturbing; it has such a large beta coefficient by itself, but it is not significant: an indication that a large interaction is possible.
Neurodevelopmental diagnosis (vs. none)
β = −4.03 (95% CI: −9.11, 1.04) — Model 2, %LEFW (Table 1)
β = −3.20 (95% CI: −8.39, 1.99) — Model 2, fluorosis (Table 2)
Multiple imputation model:
β = −1.56 (95% CI: −3.37, 0.26) — Table 8
β = −1.25 (95% CI: −3.07, 0.58) — Table 9
Interpretation:
Across all models, having a neurodevelopmental diagnosis is associated with lower IQ scores—up to a 4-point deficit, though not always statistically significant.
In stratified analyses, the model shows paradoxical findings: children with a diagnosis showed a positive association between fluoride exposure and IQ:
β = +16.37 (95% CI: 5.52, 27.23) for 100% LEFW
β = +19.60 (95% CI: 1.48, 37.71) for fluorosis
This is biologically implausible and almost certainly the result of small sample size (n = 55), model overfit, or reverse confounding due to collider bias or effect heterogeneity
Evidence Level Disparity Between Covariates and Main Effect
The pattern of seeing exposures exonerated by these statistical tricks is tiresome. It’s a little odd how epidemiology gets away with blithe and casual model specification using covariates. We tend to see this behavior when the exposure is widespread and politically divisive. When the consumer correctly attributes causality, but science lags behind, the scientific stalemate move is like sacrificing a queen to save the king. In these cases, the reliability and reproducibility of certain studies in science are sacrificed, but the exposure continues due to obfuscation. Stalemates do not change policy.
Key to this is the assumption that causality can be attributed to covariates within the context of a study that is pitched as testing causality of a main effect. A moment’s reflection will help any true Scotsman understand that adjusting a model for covariates without prior evidence of the correct casual pathway invokes circular logic in denying causality to the main effect due to attributing causality to the confounder (even those labeled covariates) based on mere assumption. Within the context of a single study, it’s a perfect example of confirmation bias to hack away at a model’s residual variance with confounders and covariates until an association goes away. The entire modeling space explored must be reported: It only costs electrons, and then the entire model space lattice of results reported. Then everyone can participate in model selection based on objective criteria.
It’s worth mentioning also that stratification cannot be used to exonerate an effect in subgroups if the sample size and a priori power is not established before peeking at the p-value for a subgroup analysis.
Collider Bias Masquerading as Control
In causal inference, a collider is a variable that is caused by two other variables. Adjusting for it can create a false relationship between them.
The author’s data shows that brushing behavior is influenced by socioeconomic status (SES) and fluoridation policy. Parents in fluoridated communities are more likely to adopt fluoride-positive behaviors. Wealthier, more health-conscious parents are more likely to brush their children’s teeth regularly. This makes early brushing a collider—a variable influenced by both the exposure and its social determinants. Problems can emerge, especially if the relationship is nonlinear.
Conditioning on a collider creates a false statistical pathway:
Water Fluoridation → Brushing ← SES → IQ
Adjusting for brushing opens this backdoor, allowing unrelated socioeconomic advantages (which tend to increase IQ) to flow into the model and artificially weaken the fluoride–IQ relationship. In statistical terms, this is collider stratification bias. In practice, it’s causal vandalism.
Even if brushing weren’t a collider, adjusting for it would still constitute overadjustment—because it lies on the causal path from fluoride to IQ. Imprecise measurement of brushing behavior may also introduce differential misclassification, further weakening the reliability of the adjustment.
The study’s supplemental tables report a seemingly paradoxical finding: children who brushed less than twice daily at age two scored slightly lower on IQ tests. At first glance, this suggests that more exposure to fluoride from toothpaste might be associated with higher IQ—implying safety or even benefit. But neurodevelopmental disorders can imply learning or motor deficits. The effect is likely also socially structured via the effects of income. Toothbrushing frequency is a behavioral proxy tightly correlated with parental education, income, and health literacy—all strong predictors of child cognitive development. It is also influenced by community water fluoridation and public health messaging. As such, brushing frequency is not just a mediator—it is a collider, shaped by both fluoride exposure and non-exposure-related predictors of IQ. Including it in the regression model induces collider bias, pulling socioeconomic advantage into the exposure pathway and distorting the estimate. Far from exonerating fluoride, this negative beta for lower-frequency brushers confirms that part of the exposure was absorbed into a variable that cannot be separated from privilege. Brushing should be considered part of the full fluoride exposure.
A measure of collinearity would have been appropriate.
No interaction terms (e.g., Fluoride × SES) were tested in the regression models. No likelihood ratio tests or interaction p-values were reported. Stratification is not a substitute for modeling interaction: it reduces power, invites selection bias, and does not quantify heterogeneity.
The journal should have caught this. We need to insist on transparency with full accountability for model parameterization, model selection and objective model evaluation disclosure.
Their study was large enough to use machine learning (ML) to see if their models were accurate in predicting IQ; an objective ML-based approach would identify the combination and weights of variables and their interactions nimbly with less than 60 seconds of computational runtime.
While the authors employed multiple imputation for missing covariates, they did not test whether the pattern of missingness altered the exposure–outcome relationship. Nor did they explore the robustness of their results to varying imputation assumptions.
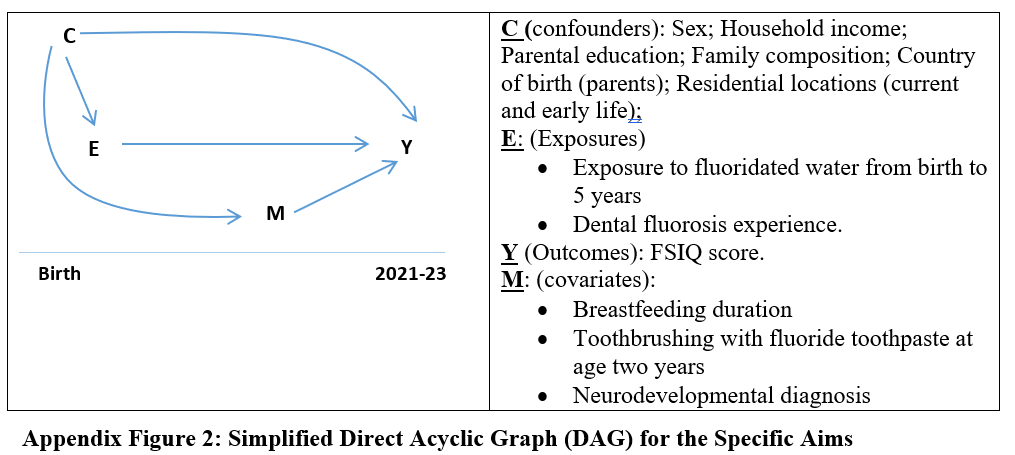
Figure X. Directed Acyclic Graph (DAG) from Do et al. (2024), Critiqued
This DAG, presented in the study as description of model structure, contains multiple methodological and conceptual flaws. It misclassifies brushing with fluoride toothpaste and neurodevelopmental diagnosis as covariates (M), rather than recognizing their plausible roles as mediators or colliders in the causal chain from fluoride exposure (E) to cognitive outcome (Y). Brushing at age two is itself a source of fluoride intake; adjusting for it obliterates part of the exposure signal and risks collider stratification bias—especially if the cumulative effect is nonlinear. Given its correlation with socioeconomic status (C), their interaction could make a positive effect negative. Residuals removed by including having a neurodevelopmental disorder as a mediator may appear to exonerate fluoride, but interaction term p-values (ND x F) would tell the full story.
The study adjusted for all covariates in a fixed model without testing for interaction terms or reporting variance inflation factors (VIF), both of which are standard components of multivariate regression diagnostics. These omissions raise serious concerns about multicollinearity and unexplored heterogeneity of effect. The authors also failed to consider gene × environment interactions (e.g., MTHFR, COMT variants) despite relevant literature and did not include community-level structural drivers such as fluoridation policy or health messaging in the DAG. Finally, the diagram’s temporal flattening conflates pre-exposure determinants, co-exposures, and post-exposure diagnoses without accounting for time-sequenced causality.
Obviously, vaccines x fluoride interaction cannot be studied if vaccines are not included.
These decisions render the study, and the DAG not merely incomplete but structurally misleading—allowing key fluoride exposure pathways to be adjusted away, thereby biasing the estimate toward null and undermining the model’s causal validity.
No Causal Model, No Sensitivity Check
This entire architecture collapses under basic causal inference standards. There is:
No evidentiary basis for their DAG.
No separation of mediators from confounders in epistemic treatment,
No interaction terms studied between covariates and fluoride,
No stratification by source of exposure (topical vs systemic),
No mention of gene × environment exploration, even though gene–fluoride interactions are well documented in the literature (e.g., MTHFR, COMT polymorphisms).
A robust study would treat brushing as part of the exposure pathway and model cumulative fluoride intake holistically. This one slices it out, potentially leaving nonlinear residuals, large but structured error terms, and then declares no harm found.
The Illusion of Equivalence
The authors go one step further by declaring equivalence—that fluoride exposure is not just non-harmful, but equally safe as no exposure. But equivalence depends entirely on the margins defined by the researchers. In this case, a range of ±5 IQ points was used. That may seem narrow, but a 5-point IQ shift at the population level is massive—comparable to the effect of lead exposure or severe nutritional deficiency. The use of such margins is statistically permissive and epidemiologically reckless.
Equivalence also assumes homogeneity of effect across the population. It assumes that every child responds to fluoride the same way. But if there is a gene–environment interaction, and only a subset of children are susceptible, then the average effect will be diluted by the unaffected majority. In other words, the null result could conceal real and serious harm to the vulnerable.
A Historical Parallel: The Brand-Specific Cigarette Fallacy
To understand the absurdity of adjusting for toothpaste fluoride in a fluoride–IQ model, consider this:
Imagine a study evaluating whether smoking causes lung cancer. The researchers decide to adjust for whether the subject had previously smoked a different brand of cigarette. They claim (or imply) this somehow “controls for smoking behaviors.” Or worse, they say they did it to “to investigate its potential effect”. Or maybe they do not say anything more about why, providing no a priori evidence of causality. In any case, they’ve stripped out the actual exposure: cigarettes. Or, likely, they have removed individuals who have genetic x exposure risk. Or reduced cumulative exposure. Or all three.
The study then focuses on the model then reports no link between smoking and cancer.
This is the fluoride equivalent.
Brushing with fluoridated toothpaste is not noise. It is the very signal you’re supposed to measure. Removing it, then declaring the remaining effect null, is not science—it’s (potentially) statistical erasure.
The Real Cost of Analytic Misdesign
Why does this matter?
Because studies like these are used to set policy. They are cited in regulatory reviews, water fluoridation recommendations, and public health messaging. When a model is designed to remove the signal, it doesn’t just fail to detect harm—it prevents its discovery. It allows plausible risk to be ignored, dismissed, and eventually legislated away.
This is not the first time fluoride safety has been defended with models that adjust away the exposure itself. But it may be the clearest. The brushing variable is not just a technical error—it is the pivot on which the study turns from science to public relations.
Closing
“After adjusting for” are the three most dangerous words in public health after “Fauci said so”. Science advances when models reflect reality. This model does not. “This study didn’t forget the murder weapon. It hid it in plain sight—and then ruled the victim died of natural causes. The authors did not perform standard, objective model selection. Options exist, like Mallow’s Cp, Akaike information criterion, and others, which are better than “we got the result we wanted”. Studies that break the very exposure it sets out to measure replace causality with a sterilized coefficient and pollute the scientific literature with false results.
This is not exoneration. This is erasure.
We owe children better than a statistical shield made of toothpaste.
Making matters worse, no data availability statement was included in the paper or supplement, despite prevailing standards requiring that authors disclose how data may—or may not—be accessed. This absence further insulates the model from independent scrutiny.
Related:
What a More Fully Specified and Evaluated Modeling Exercise Looks Like
Related:
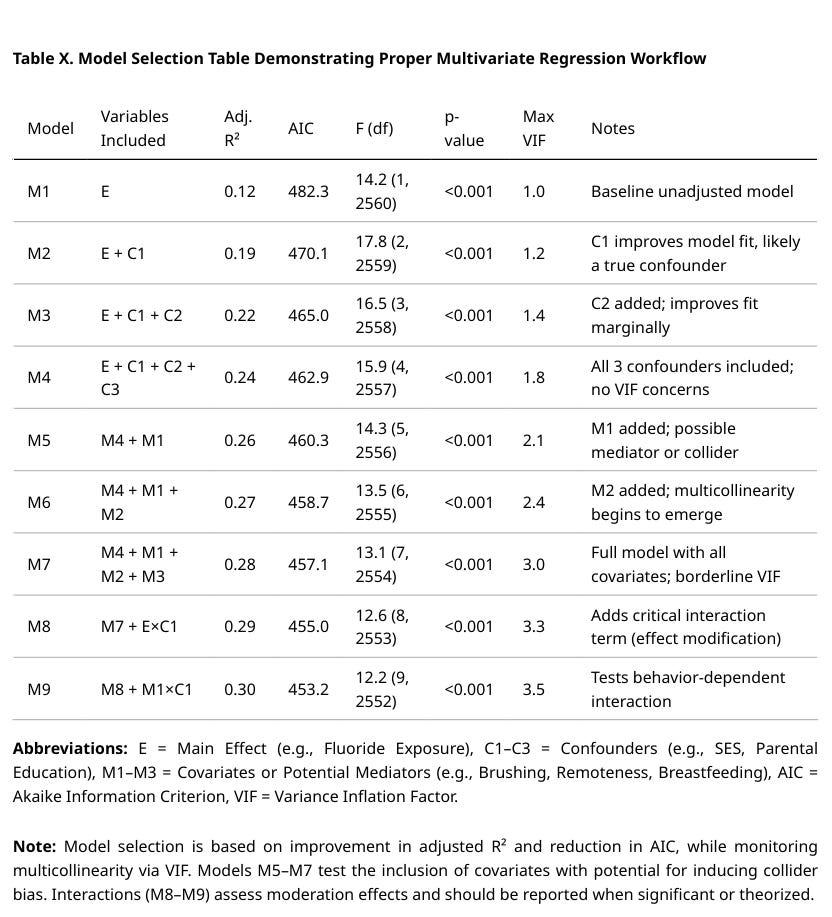
Here’s a PopRat extra: A table showing how to present models specified prior to selection. NOT REAL DATA.
Study Citation: Do LG, Sawyer A, John Spencer A, et al. Early Childhood Exposures to Fluorides and Cognitive Neurodevelopment: A Population-Based Longitudinal Study. Journal of Dental Research. 2024;104(3):243-250. doi:10.1177/00220345241299352

Human disease is pluri-causal The neurotoxicity of fluoride AND aluminium is irrefutable. Their neurotoxicity is likely to be synergistic. If we are serious about trying to make America healthy again, both fluoride and aluminum exposure must be eliminated.
Thank you for shedding light in another area of this war against objective reality. There ought to be predefined, objective mechanisms in place that negatively rate a journal that would publish such a "study", and funding mechanisms that would eventually dissolve them into non-existence when they do. You lay out clearly how this ought to have been conducted, but then again, I don't think there would ever have been such a study were it not for someone funding it to present the desired conclusion. Also, absence of data availability should be an automatic disqualification. I'm sure they hide behind the canard of "data privacy", but standardized and even 3rd party validated anonymization could readily assure this - combined with replication from competing researchers, which should be a requirement on the public health policy side of the equation. What would it take to affect such reasonable changes to the landscape in how retrospective epidemiological studies are conducted?